| |
In this lab, we will examine:
Recommended web links:
Confidence Interval Applets: Experiment
with confidence intervals and signficance levels.
The main goal of inferential statistics is to make inferences about population parameters based on sample data. There are two ways of making inferences about a population:
Both methods reply upon probability and the sampling distribution theory
that we explored in previous labs. In this lab, we will concentrate on estimation methods.
In the next lab, we will examine hypothesis testing, which will form the basis
for all subsequent statistical methods examined in this course.
There are two types of estimation procedures:
A single number, calculated from the sample data, is used as the best estimate of a population parameter. Point estimates can be developed for:
1. Population mean ![]() : There are several ways of
estimating
: There are several ways of
estimating ![]() . You could use the median,
the mode or the mean. However, if a sample is randomly selected from the
population and has a normal frequency distribution, there is a high probability that
the sample mean
. You could use the median,
the mode or the mean. However, if a sample is randomly selected from the
population and has a normal frequency distribution, there is a high probability that
the sample mean ![]() is close to the
mean of the sampling distribution. The central limit theorem tells us that the mean of the
sampling distribution equals the population mean
is close to the
mean of the sampling distribution. The central limit theorem tells us that the mean of the
sampling distribution equals the population mean
![]() . Therefore,
. Therefore,
![]() is the best estimate of
is the best estimate of ![]() .
.
2. Population proportion ![]() : The best estimate of a
population proportion is the sample proportion, p, calculated from
the sample.
: The best estimate of a
population proportion is the sample proportion, p, calculated from
the sample.
Point estimates are useful as they give us an estimated value for the parameter
of interest (mean or proportion). We know that a statistic calculated from any
one sample (![]() or p) will be close to the
value of the population parameter (
or p) will be close to the
value of the population parameter (![]() or
or ![]() ). However, it is unlikely
that a sample statistic will be identical to the population parameter and we
may doubt the accuracy of our estimate. Therefore, it is useful to define a
range or interval around our point estimate that is likely to
include the population parameter.
). However, it is unlikely
that a sample statistic will be identical to the population parameter and we
may doubt the accuracy of our estimate. Therefore, it is useful to define a
range or interval around our point estimate that is likely to
include the population parameter.
Two numbers define the interval within which the population parameter is thought to lie with a certain probability.
From Lab 3, we know that if we draw several different samples from the same
population, the statistics calculated from each sample will differ. However,
using information on probabilities and sampling distributions, we can specify
an interval around our best estimate (![]() or p)
so that there is a high probability that the population parameter lies within
the interval. In other words, P(interval contains population parameter) =
0.95.
or p)
so that there is a high probability that the population parameter lies within
the interval. In other words, P(interval contains population parameter) =
0.95.
We will continue with the stream example from above where our best estimate of mean velocity was 10.8 m/sec.
The sample of stream velocity contained 25 measurements. Imagine that we
collect 9 additional samples, where each sample contains a different set of
25 velocity measurements. These 10 sample means will differ slightly, because
each sample contains observations. We will place the ![]() 2 m/sec interval around each sample mean. The sample means and their associated
intervals are outlined in the table below.
2 m/sec interval around each sample mean. The sample means and their associated
intervals are outlined in the table below.
| Sample | Sample mean (best estimate of | Interval ( |
|---|---|---|
| A | 10.8 m/sec | 8.8 to 12.8 m/sec |
| B | 9.0 m/sec | 7.0 to 11.0 m/sec |
| C | 11.9 m/sec | 9.9 to 13.9 m/sec |
| D | 13.5 m/sec | 11.5 to 15.5 m/sec |
| E | 8.4 m/sec | 6.4 to 10.4 m/sec |
| F | 10.4 m/sec | 8.4 to 12.4 m/sec |
| G | 8.1 m/sec | 6.1 to 10.1 m/sec |
| H | 10.3 m/sec | 8.3 to 12.3 m/sec |
| I | 9.3 m/sec | 7.3 to 11.3 m/sec |
| J | 11.5 m/sec | 9.5 to 13.5 m/sec |
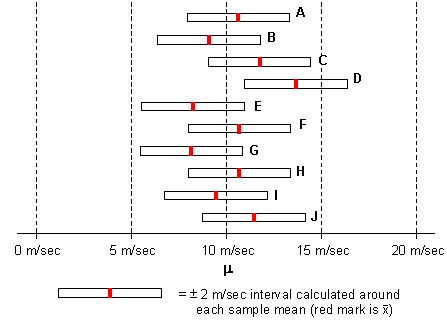
The diagram below shows the sample means and the intervals graphically. For
the sake of this example, assume that we know the true mean stream velocity
(![]() ) is 10.0 m/sec. Notice that
9 of the intervals contain the true population mean. Only the interval for
Sample D does not contain the true population mean.
) is 10.0 m/sec. Notice that
9 of the intervals contain the true population mean. Only the interval for
Sample D does not contain the true population mean.
|
If a sample mean is less than 8 m/sec or greater than 12 m/sec, the 2 m/sec
interval around the mean will not contain the population mean. However, the
probability that any sample mean is less than 8 m/sec or greater than 12 m/sec
is fairly low. As we see in the diagram above, the ![]() 2 m/sec interval contains the population mean 9 times out of 10 (so the probability
is 0.90).
2 m/sec interval contains the population mean 9 times out of 10 (so the probability
is 0.90).
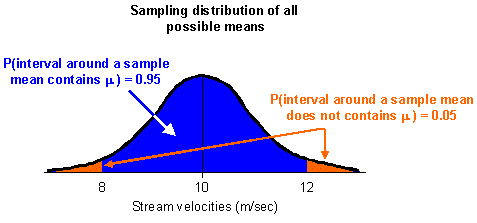
Imagine we drew 100 samples and found that the ![]() 2 m/sec interval around the means contains the population mean 95 times out
of 100. We could say there is a 95% probability that the interval around a
sample mean contains the population mean. If we drew all possible samples
from this population, we may find that the probability that the
2 m/sec interval around the means contains the population mean 95 times out
of 100. We could say there is a 95% probability that the interval around a
sample mean contains the population mean. If we drew all possible samples
from this population, we may find that the probability that the ![]() 2 m/sec interval placed around each sample mean contains the population mean
is also 0.95 (see the diagram below).
2 m/sec interval placed around each sample mean contains the population mean
is also 0.95 (see the diagram below).
|
The probability value gives us a measure of confidence in the accuracy
of our stream velocity estimate. With this interval, we can say "we estimate
with 95% confidence that stream velocity in the Goldstream River is 10.8 m/sec
![]() 2 m/sec". We call this interval the confidence
interval around our estimate.
2 m/sec". We call this interval the confidence
interval around our estimate.
In the example above, the size of the interval was given. In reality, you will not know how wide the interval should be. You could determine the size of the confidence interval by drawing all possible samples, plotting the sample means on a number line and finding the exact interval that contains 95% of the sample means. However, because we know that the sampling distribution of means follows the normal distribution (from the Central Limit Theorem), you can draw one sample and use a formula that incorporates Z scores to calculate a confidence interval around your best estimate.
Before we work with the formula, we need to examine the confidence interval probabilities
more closely.
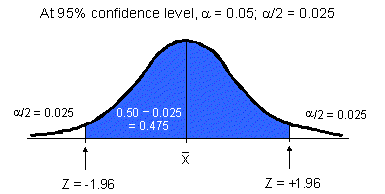
Confidence intervals can be developed for any probability level:
These probabilities are called confidence levels and are expressed as
(1 - ![]() ).
The symbol
).
The symbol ![]() (called 'alpha') refers to the probability that the
parameter is outside the interval. When
(called 'alpha') refers to the probability that the
parameter is outside the interval. When ![]() = 0.05, the
confidence level is (1 - 0.05) = 0.95 or 95%. Alpha is also known as the significance level.
= 0.05, the
confidence level is (1 - 0.05) = 0.95 or 95%. Alpha is also known as the significance level.
| Significance Level ( | Confidence Level | |
|---|---|---|
| 0.10 | (1 - 0.10) = 0.90 or 90% | |
| 0.05 | (1 - 0.05) = 0.95 or 95% | |
| 0.01 | (1 - 0.01) = 0.99 or 99% |
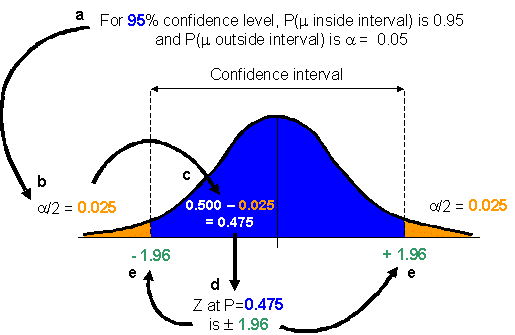
When calculating a confidence interval, ![]() is evenly
divided between the two sides of the sampling distribution. Therefore, the probability
that the population mean is less than the confidence interval is
is evenly
divided between the two sides of the sampling distribution. Therefore, the probability
that the population mean is less than the confidence interval is ![]() divided by 2; the probability that the population mean is greater than the confidence
interval is also
divided by 2; the probability that the population mean is greater than the confidence
interval is also ![]() /2.
/2.
Since the sampling distribution has the same shape as a normal distribution, you can express the confidence level probabilities using a Z score (from the standard Z distribution). To do this, you need to find the value of Z that defines your confidence interval. The steps to finding Z for a 95% confidence interval are outlined below and in the accompanying diagram.
|
In the steps outlined above, we used the standard normal probability distribution (Z distribution) to model the probabilities in the sampling distribution. However, with a small sample, the probabilities associated with the Z distribution may underestimate the true variation in the population. For small samples, it is more appropriate to use the t-distribution. Therefore, we use the following rule when developing confidence intervals:
The break between large and small samples (![]() 30) is not an absolute rule. It is a guideline or convention used by many
statisticians. Any analyst could disregard the guidleline as long as he
or she can provide a reasonable justification (e.g. you might use the t-distribution
for a sample of n=35 because you want to be more conservative in your estimate).
30) is not an absolute rule. It is a guideline or convention used by many
statisticians. Any analyst could disregard the guidleline as long as he
or she can provide a reasonable justification (e.g. you might use the t-distribution
for a sample of n=35 because you want to be more conservative in your estimate).
Important note:
Confidence intervals should only be developed for variables with normal or approximately
normal distributions. If the sample distribution is non-normal (highly skewed or bimodal), you
should not calculate an interval.
In this lab, we will calculate the following confidence intervals:
Note: In Lab 2, we started with an interval on the Z distribution and calculated the probability within the interval. In this lab, we start with a probability (or confidence level) and calculate the interval for this probability.
a) Confidence interval around a mean:
This formula is used to calculate confidence intervals (CI) for large samples:
| Formula: | 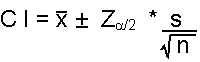
| where: desired confidence level s = sample standard deviation n = sample size |
|
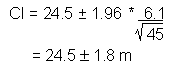
The confidence interval has a lower limit of 22.7 m (24.5 - 1.8) and an upper limit of
26.3 m (24.5 + 1.8). We estimate with 95% confidence that the true mean tree height is
between 22.7 m and 26.3 m.
b) Confidence interval for a proportion:
The confidence intervals for proportions are constructed in a similar way to the
intervals for means. The confidence intervals for proportions should only be calculated for
very large samples (n>100).
For smaller sample sizes, the sampling distribution of ![]() follows the binomial probability distribution (we are not covering this distribution in this course).
follows the binomial probability distribution (we are not covering this distribution in this course).
For a large sample, the formula is:
| Formula: | 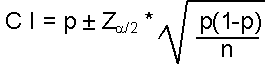
| where: p = sample proportion (best estimate of desired confidence level n = sample size |
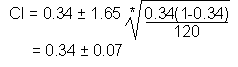
The confidence level has a lower limit of 0.27 (0.34 - 0.07) and an upper level of 0.41 (0.34 + 0.07). We estimate with 90% confidence that the true proportion of teenage customers who shop at ACME Music lies between 0.27 and 0.41.
c) Confidence interval for a mean (small sample):
The formula for small sample confidence intervals is:
| Formula: | 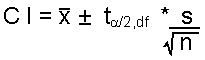
|
where: |
Example: Calculate the 95% confidence interval for a sample (n=15) of stream channel
depths, where ![]() = 130 cm and s = 31 cm.
= 130 cm and s = 31 cm.
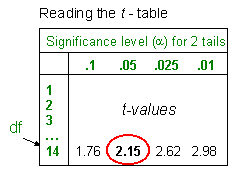
|
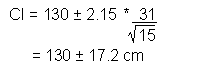
The confidence interval has a lower limit of 112.8 cm and an upper limit of 147.2 cm. We estimate with 95% confidence that the mean stream channel depth is between 112.8 cm and 147.2 cm.
d) One-tailed confidence intervals
The confidence intervals calculated above are considered two-tailed intervals as the
![]() probability covers both end (tails) of the distribution. This
is the standard type of confidence interval. However, one-tailed confidence intervals
(lower or upper limit) can be calculated if you are interested in a minimum or maximum value only.
probability covers both end (tails) of the distribution. This
is the standard type of confidence interval. However, one-tailed confidence intervals
(lower or upper limit) can be calculated if you are interested in a minimum or maximum value only.
In this case, we are only interested in maximum emissions. Therefore,
we will use an upper confidence limit to see if the mean car emissions
are higher than the allowable level.
This diagram shows the difference between a two-tailed confidence interval and a one-tailed upper confidence bound for the same confidence level:
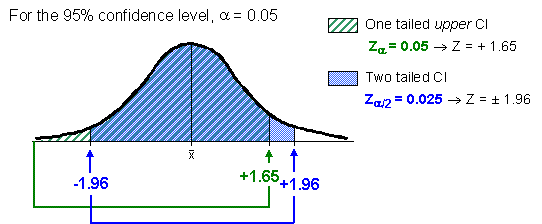
|
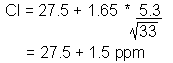
From this sample, we estimate with 95% confidence that the maximum mean carbon monoxide emission is 29.0 ppm; this car model (just) meets emission standards.
Remember that your confidence interval is based on one sample. There is a small probability (1%, 5%, etc.) that your sample mean or proportion actually falls at an extreme end of the sampling distribution. If you are using your confidence interval or estimate to recommend a course of action, it is often a good idea to take more samples to confirm the original estimate or inteval.
| OR |
Practice Questions
Q1. Complete the table below:
| Estimate | Interval type | Confidence level | n | Z or t? | Z or t value | ||
|---|---|---|---|---|---|---|---|
| A. | two tailed | 90% | 45 | ||||
| B. | two tailed | 95% | 12 | ||||
| C. | one tailed | 95% | 36 | ||||
| D. | p | two tailed | 99% | 180 | |||
| E. | two tailed | 80% | 60 | ||||
| F. | one tailed | 99% | 23 |
Q2. Calculate the following confidence intervals:
Answers
Question 1
| Z or t? | Z or t value | ||
|---|---|---|---|
| A | 0.10 | Z | 1.65 |
| B | 0.05 | t | 2.20 |
| C | 0.05 | Z | 1.65 |
| D | 0.01 | Z | 2.58 |
| E | 0.20 | Z | 1.28 |
| F | 0.01 | t | 2.51 |
Question 2:
| © University of Victoria 2000/2001 Updated: October 4, 2002 |