|
|
In this lab, we will consider:
Recommended web links:
BC Resources Inventory
sampling: Visit the BC Resources Inventory Committee sampling procedures
for vegetation, estuaries, streams, etc.
New York City water:
Learn about the NYC watershed protection and water sampling program.
Hanford Nuclear Reactor Site: Visit the
environmental monitoring and sampling program by clicking on the Surveillance headings.
Sampling Distribution Applet: Explore the dynamic between
samples and the sampling distribution of statistics.
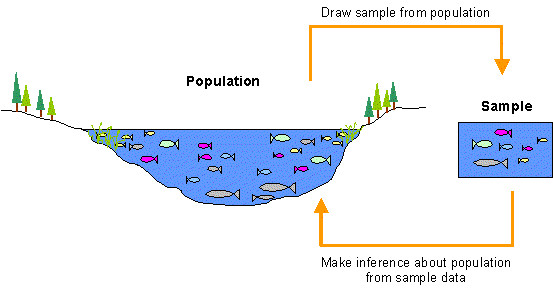
Generally, geographers collect and analyze two different types of data: population data and sample data. A population is the complete set of objects (people, regions, rivers, households, fish, etc.) under study. If you collect information on all objects in the population, you would be conducting a census. However, it is often impossible to collect data for an entire population (exactly how many fish are there in a lake and how do you catch them all?). In these cases, researchers rely upon samples, which are subsets of the population.
Assuming that a sample is representative of the population, analysts can use information obtained from the sample to make inferences about the values of particular characteristics in the population. The reliability of the inferences, however, closely depends on how well the sample data have been collected.
|
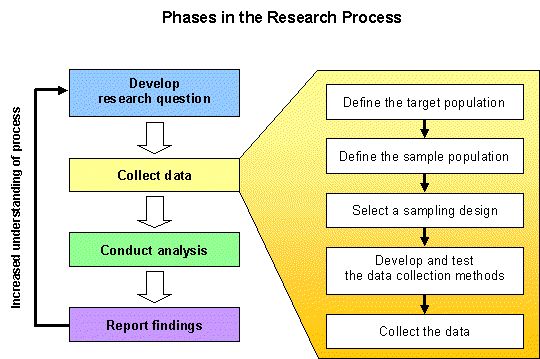
Once you have defined your research framework, you will have a better idea of which sampling and analysis methods to use. Remember, good planning at the beginning will make all the difference between high quality research and a mess. This lab will focus on the sampling phase of the research process.
|
1. Define the Target Population:
The target population is the complete set of individuals from which you want to collect
information. This definition is usually established at the conceptual level.
2. Define the Sample Population:
The sample population is a practical or operational definition of the target population.
Your target population includes all individuals you want to study, but the sample population
establishes a list of exactly who you will study. Defining your sample population is often
challenging because there is rarely a list that contains all individuals in your target population.
Ideally, you want your sample population to contain all individuals in your target population. If not, you may introduce bias or error into your sampling. How much bias may be introduced if you exclude people without telephones? Perhaps a little, perhaps a lot... it may depend on your population and the question(s) you are asking.
It may seem easier to define the sample population for physical phenomena (forestry, ecology, fisheries, weather, etc) because you can 'see' the population. For example, if you are conducting forestry research in a watershed, you could say that the population includes all trees within the specific drainage basin.
However, you must still specify the sample population. Will you sample in swampy areas? what about ridge tops and rocky areas? what about young trees growing in a clear-cut or fire scar? If you exclude these areas, you will not be able to generalize or make inferences about 'all trees' in the watershed. To simplify you may decide to focus on a particular species or age group (i.e. fir and hemlock stands between 30 and 150 years of age). Now you must have precise maps identifying these stands.
Typically, considerable time and energy is spent defining the sample population
and obtaining lists and/or maps before data collection starts.
3. Select a sample design:
A sample design is the method used to select individuals from the sample population. This
is a crucial step in the sampling process. There are two groups of sample design:
non-probability and probability designs.
In non-probability sampling, individuals are selected by the researcher. Subjective selection may be conducted if some individuals have personal experience or background knowledge that would contribute to the research or if the research is focusing specifically on a group of people or a region (i.e. a case study).
Probability sampling requires the objective selection of individuals from the sample population. Using these methods, a researcher can determine the probability of selection probabilities and calculate sampling error. Inferential statistics require the use of probability sampling designs.
4. Develop and test data collection methods:
If you are collecting information using a questionnaire or interviews, the questions must be
carefully worded and tested for logic and clarity. If you are using instruments, the instruments
must be calibrated and tested to ensure accuracy. Sampling procedures must be developed to ensure
consistent data collection. It is a good idea to conduct a pre-test or pilot test to work
out any bugs in the questions, instruments or procedures.
5. Collect the data:
If all goes according to your plans above, data collection should be relatively straight forward.
You will also want think about how you will process or enter the data.
A. Non-probability Sampling
The essential characteristic of these methods is that the probability of an individual being
selected for the sample is unknown. Assume that you have been asked to investigate the
attitude of UVic students towards installing a baseball diamond on campus.
Non-probability sampling designs include:
1. Purposive sampling: personal judgment is used to decide which individuals in the population are selected. The analysts picks individuals whom it is felt best serve the purpose of the sampling exercise.
2. Convenience sampling: only individuals who are easily accessible are sampled.
3. Volunteer sampling: people elect themselves for the sample.
Important descriptive results may be obtained from a non-probability sample. However, the concern that arises with the use of non-probability samples is sampling bias, which means that the individuals selected may not be representative of the entire student body.
B. Probability Sampling
The important characteristic of these methods is that the probability of selecting an
individual (person, tree, fish, household, etc.) from the population for inclusion in the sample can be determined.
When you know the selection probabilities, you can estimate the probability that your
sample is or is not representative of the population.
1. Simple random: each individual has an equal chance of being selected for the sample. There are several ways to select a random sample (you could draw numbers from a hat) but the best way is to use a random number table. These tables are a computer-generated list of digits where every number (0 to 9) has an equal chance of occurring. To draw a random sample:
The drawback of simple random sampling is the chance that the individuals (people, trees, fish) in your sample may not representative of the population. The diagram below shows two samples of plots for soil research, selected in a study area. As the selected soil plots in Sample H are evenly distributed across the study area, they will likely be more representative of the types of soil found in the study area. The plots selected in Sample Q are located mostly in the dry areas, which will introduce bias into the data.

|
2. Systematic random: every Xth individual is selected from the list, starting at a randomly chosen point.
One limitation of systematic sampling is that regular fluctuations or cycles in the phenomenon may be emphasized or missed by this method.
c. Stratified random: sometimes the population may contain two or more different groups that are of interest to you. If so, you can divide your sampling frame into strata or classes, and then select a random sample from each stratum. The strata are defined so that individuals inside each class are similar (internally homogeneous). Stratification is usually based on a characteristic believed to influence the phenomena that you are investigating or a natural grouping of observations.

|
This method will provide you with a random sample for the valley and a random sample for the hillsides. The stratified random method provides the best results because it ensures even coverage of the population but maintains the random selection probabilities.
d. Cluster sampling: this method is used when stratified or simple random sampling would be difficult and/or expensive to implement. The population is divided into groups or clusters, which are assumed to be similar to each other. Clusters are then randomly selected for detailed study. Within a cluster, you may select each individual or take a random sample of individuals.
For the next 3 examples, assume that our population consists of 20 households in a neighbourhood. We will use combinations to determine the number of households you can select in a sample.
1. How many different samples of 4 households can you select?
There are 2 notational conventions: or or
| 
| where n = number in master set (i.e. population) k = number in subset (i.e. sample) ! = factorial operation (see below for explanation) |
Note: the symbol n! (�n factorial�) is defined as n! = n * (n-1) *
(n-2) *� 2 * 1.
Example: 6! = 6 * 5 * 4 * 3 * 2 * 1 = 720.
As combinations are cumbersome to calculate by hand, use the combinations
(either nCk or nCr) button on your calculator:
Using the combination formula to calculate the number of different 4 households samples you could select, we get:
 |
| There are 4,845 possible combinations of 4 households from the 20. |
2. If 7 houses are located on Franklin Street, how many samples of size 4 can you draw?
3. How many different samples of 10 can you select from the 20 households?
Knowing the number of possible samples is important as it helps you to understand sampling
probabilities and distributions, which we will examine below.
In the language of statistics, a numerical summary calculated for a sample is called a statistic; a numerical summary for the population is called a parameter. The table below gives the formulas for the mean, standard deviation and proportion for samples and populations.
| Sample | Population | |
|---|---|---|
| Name | Statistic | Parameter |
| Mean | 
| 
|
| Standard deviation | 
| 
|
| Proportion | nA = number of occurances of A in sample | NA = number of occurances of A in population |
| n = sample size | N = population size |
Note: For the sample standard deviation, s, you divide by n-1. This gives you a slightly
larger standard deviation (a smaller denominator means a larger s value). As a sample
is only a subset of the population, you cannot be certain that your sample
is representative of the population. If you use n in the formula for the sample standard
deviation, you may underestimate the true variation that exists in the population.
When you calculate ![]() , there is no danger of underestimating the
variation because you are using all values in the population. Therefore, you can use N.
, there is no danger of underestimating the
variation because you are using all values in the population. Therefore, you can use N.
Population parameters (![]() or
or
![]() )
have only one value. However, there are many possible values for the sample statistics
(
)
have only one value. However, there are many possible values for the sample statistics
(![]() or s). Each sample contains different
individuals, which means that the values of your statistics will vary from one sample to
the next. Recall from the household example above, there were 4,845 possible samples
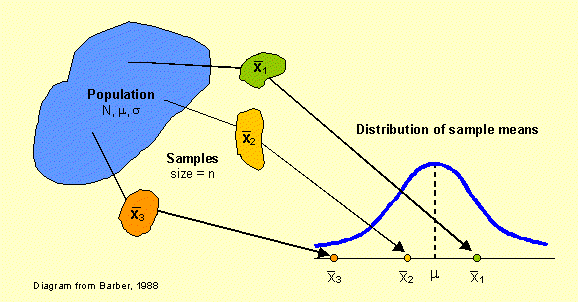
of n=4 households. Imagine that you drew each sample and calculated every sample mean.
This collection of statistics will form a sampling distribution of means.
If you constructed a histogram of these means, what shape would you expect for this
distribution? Perhaps a normal curve?
or s). Each sample contains different
individuals, which means that the values of your statistics will vary from one sample to
the next. Recall from the household example above, there were 4,845 possible samples
of n=4 households. Imagine that you drew each sample and calculated every sample mean.
This collection of statistics will form a sampling distribution of means.
If you constructed a histogram of these means, what shape would you expect for this
distribution? Perhaps a normal curve?
|
Sampling distributions can be developed for any statistic (mean, standard deviation, total, proportion, etc.). However, the sampling distribution of means is the most important for sampling theory and inferential statistics. The general characteristics of the sampling distribution of means are summarized by the Central Limit Theorem.
This theorem describes the properties of a sampling distribution of means:
| Formula: | 
| where n = sample size |
| In the formula above, you can see that sample size influences the size of the standard error. As sample size increases, the standard error decreases - this relationship is shown in the diagram to the right. Larger samples usually have more accurate means than smaller samples; if you sample 100 people, your mean will likely be closer to the population mean than if you sample only 5 people. |  |
The Central Limit Theorem is useful in the following ways:
In other words, you can adjust the accuracy of your sample statistics by controlling the sample size.
Using the relationship between the standard error, sample size and the probabilities associated with the sampling distribution, you can estimate how many observations you need in your sample to achieve a certain degree of accuracy.
| Formula: | 
| where Z = standard errors from mean E = tolerable error |
Notes on the formula:
Example: As a consultant, you have been asked to estimate the mean daily
household water consumption in Sidney so that a water supply plan can be developed. Your sample mean
must be accurate to within ![]() 25 litres/day.
How many households should you sample so there is a high probability (95% probability)
that your sample mean is within
25 litres/day.
How many households should you sample so there is a high probability (95% probability)
that your sample mean is within
![]() 25
litres/day of the true mean?
25
litres/day of the true mean?
To get information for our water supply sampling, we refer to sampling conducted in 1998. The results from the 1998 study showed a mean of 300 litres/day and standard deviation of 76 litres/day. We can use the standard deviation calculated in 1998 to help determine the sample size for this study. The tolerable error, E, is 25 litres/day.
Because the sampling distribution has the same shape as the normal distribution, we
can use the Z distribution to help define an interval
that contains 95% of the sample means (i.e. the probability that any sample mean
falls inside the interval is 0.95). As we know, this interval is defined by
![]() 1.96z.
1.96z.

|
We calculate the recommended sample size as follows:

Therefore, we should select a minimum of 36 households for our sample. This sample size
will ensure our sample mean is within 25 litres/day of the true mean of household water use. In
other words, there is a only a 5% chance that the difference between our sample mean and
the true population mean is more ![]() 25 litres/day.
25 litres/day.
1. You are studying the recreational use of parks within a city. The city has 30 parks, some are small neighbourhood parks, others are larger natural parks. You want to interview park visitors to determine how, when and why they use parks. Describe the sample design you would use.
2. You are studing the nesting habits of sandpipers. There are 33 nests along the beach. You decide to count the number of eggs in 15 nests.
3. You re-analysed the data collected in the 1998 study of household water use in Sidney. You discover that the standard deviation was incorrectly calculated; you find that s = 90 litres/day.
Q1. There are several options for sample designs, including:
Q2. Sandpiper nesting habits
Q3. Water use


Download Sampling Framework Diagram (pdf)