Lab 0: Getting to Know SPSS and The SPSS Help Manual
Click the links below for SPSS Help
If you have detailed questions about any operation or test, check the HELP
function in SPSS. The Help Manual assumes that you know how to work in a Windows
environment. If you need assistance, please ask your TA.
Go to Lab 0: SPSS Practice Worksheet
I. BASIC OPERATIONS
- Go to the Start button (lower left corner of screen) to open the Start
menu.
- Move your mouse up to Programs to expand the list of software.
- Navigate to the SPSS icon and click to start.
SPSS has three main features:
- Data Editor: displays your dataset. You can add, sort, remove variables
or records, and compute new variables. The Data Editor has two tabs within
the main window (at the bottom of the screen):
Data View shows your dataset,
Variable View shows your variable names and definitions.
In a dataset, each column is a variable; each row is a record (or observation
or case).
|
| Variable 1
| Variable 2
| . . .
| Variable X
|
| Record 1
| data
| data
| data
| data
|
| Record 2
| data
| data
| data
| data
|
| . . .
| . . .
| . . .
| . . .
| . . .
|
| Record X
| data
| data
| data
| data
|
- Output: displays the results of tests or charts. You can add/delete
text or numbers and edit charts. The Output window has a navigation bar at
the side (similar to Windows Explorer) so you can move around within your
results. You can minimize, expand or delete test results.
- Main Menu: The SPSS functions are accessed from the main menu at
the top of the SPSS window. Click on the menu category and scroll down to
the item using your mouse.
- Under File, select Open
 Data.
Data.
- Navigate through the directories to the data file.
- Click OK.
- Under File, select New Data; a blank Data
Editor window will open.
Note: You can only have one dataset open at a time. If you open another dataset
or a new data window, SPSS will ask you to save your old data before closing
the file.
- From the Data Editor, click Save and navigate to the appropriate location
(i.e. your disk).
- To work on the data in another application, click Save As and specify dBase
IV (.dbf) as the file type. You can import .dbf files into MS Excel.
- From the Output window, click Save and navigate to the appropriate location.
Your file will be saved as SPSS output (.spo) which requires
SPSS to run.
- You can also copy and paste your results and charts into MS Word for later
editing.
II. DATA OPERATIONS
Insert a variable
- In the Data Editor, under Data, select Insert Variable. A generic variable
name (VAR00001) will appear at the top of a column.
- Put your cursor in the first cell of this column.
- Click to Variable View tab to define the variable.
- Specify:
- Name: use 8 characters or less
- Type: numeric, date, string (text)
- Width: maximum number of characters in this variable (default
is usually 8)
- Decimal places: maximum decimal places required (the default
is 2 decimal places).
Enter data
- Use Enter to move down the column.
- Use Tab to move along the row.
Insert a record
- Put your cursor on the row below where you want the new case.
- Under Data, select Insert Case.
Sort data
- Under Data, select Sort.
- Choose the variable and sort order:
Ascending: A 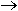 Z or low
high
Z or low
high
Descending: Z A or high
low
Create a calculated variable
- Insert a new variable
- Specify the appropriate name and format for the new variable.
- Under Transform, select Compute.
- Type the name of the new variable in the top left box.
- In the large box, create your formula. You can move variable names from
the list at the lower left and use function buttons or function list under
the formula box.
- Click OK.
- SPSS will ask to overwrite the newly created variable - click OK.
Create charts
SPSS has a range of graph and chart options. Your chart will be displayed in
the Output window.
Bar charts
- Choose the appropriate bar chart type (simple, clustered or stacked).
- Specify that data in chart are Summaries for groups of cases.
- Specify what the bars represent (number of cases, cumulative cases, other
functions, etc...).
- Under Category Axis, select the variable you want to graph.
Pie charts
- Specify that data in chart are Summaries of groups of cases and
click Define.
- Specify what the slices represent (number of cases, cumulative cases,
other functions, etc...).
- Under Define Slices by, select the variable you want to graph.
Scatter plots
- Choose Simple scatterplot.
- Move your variables to the X and Y axis.
- Under Label Cases, select the variable you want to label cases
by on the graph. See steps under Chart Editor for
more instructions.
Histogram
- Select your variable.
- Click check box (lower left) to display the normal curve over the histogram.
Note: you cannot specify the number of intervals in the histogram.
Edit charts
From the Output window, double click on your chart to enter the Chart Edit
mode. Some important functions are listed below. Some of the options vary depending
on the chart type.
Format axis - for changing the value range or increments on each axis
- Under Chart, select Axis.
- Select the appropriate axis (X or category, Y or scale).
- Specify the data range to be shown if necessary.
- Specify the division markers and increments.
Add data labels - for labelling points on scatterplots
- Under Chart, select Options.
- For scatter plots, click Case Labels ON to label each point by the variable
specified for scatter plots.
Add reference lines - for adding reference lines on scatterplots, residual
plots or bar charts
- Under Chart, select Reference Lines.
- Select the appropriate axis (X or Y).
- Type -2 in the upper box and click ADD to move the number down into the
second box.
- Type 0 and click ADD again.
- Repeat as needed.
To return to the Output window, click the close button in the top right corner
of the Chart Editor.
III. USING THE STATISTICS TOOLS
SPSS can perform many different statistical procedures. The test results are
displayed in the Output window.
Descriptive Statistics
This function calculates the standard set of descriptive statistics: 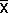 ,
s, min, max, n.
,
s, min, max, n.
- Under Analyze, select Descriptive Statistics, then select
Descriptives or Frequencies. Click OK.
- In Descriptive Statistics, you can specify other descriptive statistics
using the Options button (lower right corner of dialogue box),
- In Frequencies, you can specify statistics using the Statistics button.
Conduct random sampling
This function allows you to randomly select observations from your dataset.
In Lab 3, Question 2d asks you to select 3 different random samples of life
expectancy data (where n = 5, 20 and 100). Follow steps 1 to 6 for each sample.
Once the three samples are chosen, go to step 7.
For each sample:
- Under Data, select Select Cases.
- Choose Random Sample of Cases and click the Sample button.
- Specify the sample size as follows:"Exactly {your desired sample size}
cases from the first {the total number of observations} cases."
- Click the check box below to ensure that unselected cases are Filtered
(not Deleted) and click OK.
- A new variable (Filter) will be added to the Data Editor, where 1 = case
is selected in sample, 0 = case is not selected.
- Highlight the filter column and copy/paste it into a new column. Rename
this column (i.e. Fil_5 for "filter to select 5 observations").
Note: If you do not copy and paste the filter into a new column, SPSS will
overwrite the information when you choose your next sample.
Create the next two samples using the same procedures (steps 1 to 6). You should
have three filter variables labelled Fil_5, Fil_20 and Fil_100.
Non-parametric Tests (Goodness of Fit)
The non-parametric sub-menu lists several tests including:
- one sample chi-square
- one sample KS
- two sample chi-square
a. One sample Chi-square
- Under Statistics Non-Parametric, select
Chi-square.
- Move your variable into the Test Variable box
- Under Expected Range, keep the default selection Get from Data
- Under Expected Values, click All categories equal
- Click OK.
- In the Output window, you will see two tables. The first table contains
the observed and expected frequencies used in the Chi-square test. The residual
column is the actual difference between observed and expected - not (Obs-Exp)2/Exp.
The second table gives you the chi-square (
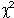 *)
and degrees of freedom (df).
*)
and degrees of freedom (df).
b. One sample KS test
- Under Statistics Non-Parametric, select
1 sample KS.
- Move your variable(s) into the Test Variable box. (You can move multiple
variables into the Test Variable box. SPSS will run a separate test for
each variable)
- Under Test Distribution, click on the appropriate expected frequency distribution
(normal, uniform, poisson or exponential)
- Click OK
- In the Output window, the results of the KS test are shown in one table.
In the hypothesis test, use the absolute difference under Most Extreme
Differences for D*, not the KS Z value. The p-value is listed as Asymp
Sig. for each variable. p-value is
c. Two or more sample Chi-square
- Under Statistics Descriptives Statistics,
select Crosstabs.
- Move your variables of interest (govt, laws, manage and title) into the
Row box
- Move the variable that distinguishes your samples (sex) into the Column
box
- Click on the Statistics button; select Chi-square (located in the
top left corner) and click Continue.
- Click on the Cells button; under Counts, select Expected and Observed
and click Continue
- Click OK to run the test
- In the Output window, you will see two tables for each variable you tested.
- First table : This is a summary of the observed
and expected frequencies calculated by SPSS. Notice that one variable
may have 4 categories of answers, whereas another may 3 categories of
answers. Use the appropriate number of categories when calculating the
number of degrees of freedom.
- Second table : This table contains the calculated
*. It is called Pearson's chi-square
and is listed in the column Value. The p-value is listed in the
column Asymp Sig..
- If you forgot to specify 'chi-square' under the Statistics button,
you will have no test results.
Parametric Tests (Difference of Means)
The compare means sub-menu lists several tests including:
- one sample t-test
- independent sample t-test
- paired sample t-test
a. One sample t-test
- Under Statistics Compare Means, select
One sample t-test.
- Select variable for test in right hand dialogue box.
- Move to Test Variable box using arrow.
- Enter the Test Value (known or hypothesized population value).
- Click OK
- In the Output window, you will see two tables. The first table contains
descriptive statistics for the variable. The second table contains the test
statistic in the column 't'. The degrees of freedom for the test are listed
under the column 'df'.
b. Independent sample t-test
- Under Statistics Compare Means, select
Independent Sample t-test
- Move the variable of interest into the Test Variable box.
- To separate the two samples within the test variable, move the variable
with the grouping criteria into the Grouping box (see example below)
- Click Define Groups and fill in the text that differentiates your samples.
Example: For the Squid dataset:
| Province
| Damage
|
| CHA
| 220
|
| CHA
| 353
|
| CHA
| 415
|
| RAY
| 279
|
| RAY
| 337
|
| RAY
| 380
|
-
To conduct the 2 sample test on the variable Damage:
-
- move Damage into the Test Variable box
- move Province into the Grouping box
- click Define Groups and type CHA in Variable 1 and RAY in Variable
2 to differentiate your groups
- SPSS will separate the two groups and treat them as separate samples
- In the Output window, you will see two tables. The first table contains
the descriptive statistics for each group. The second table contains the
two t* statistics in column 't'.
- DO NOT USE LEVENE's F*. Use the variance ratio test outlined in the
lab manual.
- If the F test indicates that the variances are equal, use the top
t*.
- If the variances are not equal, use the lower t* for the decision
rule.
c. Paired sample t-test
- Under Statistics Compare Means, select
Paired t-test.
- Click on the first variable of your pair - it appears in the Current Selections
box as Variable 1
- Click on the second variable - it appears in the Current Selections box
as Variable 2
- Click the arrow to move these variables into the Paired Variable box
- Click Ok
- In the Output window, you will see three tables. The first table contains
the descriptive statistics for each variable. The second table contains
correlations. The third table contains the mean and standard deviation of
the differences and the t* statistic in column 't'. The degrees of freedom
are listed under column 'df'.
Correlation
The Correlate sub-menu has two correlation functions:
- bivariate correlation
- partial correlation
a. Bivariate correlation (Pearson's r and Spearman's 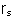 )
)
- Under Statistics Correlate, select Bivariate.
- Move the variables of interest into the Variables box (you can move multiple
variables).
- Select the test type: Pearson's r or Spearman's
- Under Test of Significance, select the direction of the test (one tailed
or two tailed). SPSS will calculate the appropriate p-values.
- Select Flag significant correlations
- Click OK
- In the Output window, you will see one table (matrix) containing the correlation
coefficients, number of observations and p-values for the selected variables.
-
-
|
| Variable A
| Variable B
| Variable C
|
| Variable A
| 1.000
--
80
|
.854**
.000
80
| -.562**
.016
80
|
| Variable B
| .854**
.000
80
| 1.000
--
80
| .254
.302
80
|
| Variable C
|
-.562**
.016
80
| .254
.302
80
| 1.000
--
80
|
Notes:
- SPSS will show a perfect r (1.000) for the correlation between the
same variable (A and A, B and B, etc)
- SPSS flags (**) correlations that are 'signficant' based on its p-value
calculation. If the p-values are very small (p=0.000...), SPSS will
indicate that the variables are significant at the 0.01 level - it changes
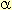 from 0.05 to 0.01).
from 0.05 to 0.01).
- The correlation matrix has a mirror image. The correlations in the
top right corner (in blue) are the same as the correlations in the bottom
left (in red).
b. Partial correlation
- Under Statistics Correlation, select
Partial.
- Move the variables of interest into the Variables box.
- Move the controlled variable into the Controlling for box.
- Under Test of Significance, select the direction of the test (one tailed
or two tailed). SPSS will calculate the appropriate p-values.
- Click OK
- In the Output window, you will see a small correlation matrix. This matrix
shows the coefficient and p-value for the correlation between the two variables
of interest, once the influence of the third variable (your controlled variable)
has been removed.
Note: the degrees of freedom are n-3 for the partial correlation.
Linear Regression
- Under Statistics Regression, select Linear.
- Before starting the analysis, you must identify your dependent and
independent variables
- Move the appropriate variables into the Dependent and Independent boxes
- Click on the Statistics button. On the right, click Model Fit and
Descriptives. Click continue.
- Click on the Plots button. Select *ZRESID for Y window and DEPENDNT for
X window. Click continue.
- Click on the Save button. Under Residuals, click Standardized and
click continue.
- Click OK
- In the Output window, you will see several tables. The important tables
are listed below.
- Descriptive Statistics: Presents
and n for each variable
- Correlations: Presents the Pearson's r correlations (and p-value)
between variables
- Model Summary: Presents r,
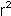 and the standard error of the estimate (in blue
- this number is used for confidence intervals).
and the standard error of the estimate (in blue
- this number is used for confidence intervals).
| Model | R | R Square | Adjusted R Square | Std. Error of the Estimate
|
|---|
| 1 | 0.909 | 0.828 | 0.800 | 152.94
|
- ANOVA (Analysis of Variance): Presents the regression, residual
and total sum of squares, the degrees of freedom and the calculated F
value (in blue) The Sig. column shows
the p-value for F*.
| Model | Sum of Squares | df | Mean Square | F | Sig.
|
|---|
| 1 | Regression | 1459528.290 | 1 | 1459528.290 | 62.396 | .000
|
| | Residual | 304089.443 | 13 | 23391.496 | |
|
| | Total | 1763617.733 | 14 | | |
|
- Coefficients: Presents the regression coefficients:
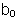 (in red) and
(in red) and 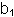 (in blue).
(in blue).
| Model | Unstandardized Coefficients
| Standardized Coefficients | t | Sig.
|
|---|
| B | Std. Error | Beta
|
| 1 | (Constant) | -1415.231
| 273.742 | | -5.170 | .000
|
| RAINFALL | 1.264 | .160 | .910 | 7.899 | .000
|
- In the Data window, you will see an extra column called ZRE-1. This column contains
the standardized residuals (the difference between each observation and the line of best
fit).
-
To prepare a residual plot if you haven't requested PLOT of *ZRESID and
DEPENDNT:
- Create a scatterplot with the dependent variable along
the X axis and the residuals along the Y axis (if you forgot to choose 'standardized residuals'
under Save when you initiated the regression function, you will not have a variable called ZRE-1).
- Add references lines at 2, 0 and -2 to the residual plot. See Chart
Editor for information about to adding reference lines to residual plots.